Chapter 1.4 데이터 핸들링 - 판다스
판다스 Pandas
- 파이썬의 리스트, 컬렉션, 넘파이 등의 내부 데이터 뿐만 아니라 CSV 등의 파일을 쉽게 DataFrame으로 변경해 데이터의 가공/분석을 편리하게 수행할 수 있게 해줌
DataFrame
- 판다스의 핵심 객체
- 여러 개의 행과 열로 이뤄진 2차원 데이터를 담는 데이터 구조체
* Index : RDMBS의 PK처럼 개별 데이터를 고유하게 식별하는 Key 값
- Series와 DataFrame은 모두 Index를 key 값으로 가지고 있음
- Series : 칼럼이 하나뿐인 데이터 구조체 vs. DataFrame : 칼럼이 여러 개인 데이터 구조체
판다스 시작 - 파일을 DataFrame으로 로딩
새로운 주피터 노트북을 생성하고 판다스 모듈을 import
! 맥북에서 Anaconda 가상환경 설정 시, pandas 모듈 미설치되었을 때!
1. 가상환경 활성화 : conda activate "자신의 가상환경 이름"
2. 'pandas' 설치 : conda install pandas
3. 주피터 노트북 실행: jupyter notebook
Kaggle: Your Machine Learning and Data Science Community
Kaggle is the world’s largest data science community with powerful tools and resources to help you achieve your data science goals.
www.kaggle.com
캐글에 접속 후, 타이타닉 탑승자 데이터 파일 내려받기
- csv 파일 중, train.csv 파일 Download -> 새로운 주피터 노트북을 생성한 디렉토리 파일 안에 내려받기
- read_csv() 함수 이용하여 csv 파일 불러오기

- head() 함수 : 맨 앞 n개의 열을 반환
- shape 함수 : DataFrame의 행과 열을 튜플 형태로 반환
- info() : 총 데이터 건수와 데이터 타입, Null 건수를 알 수 있음
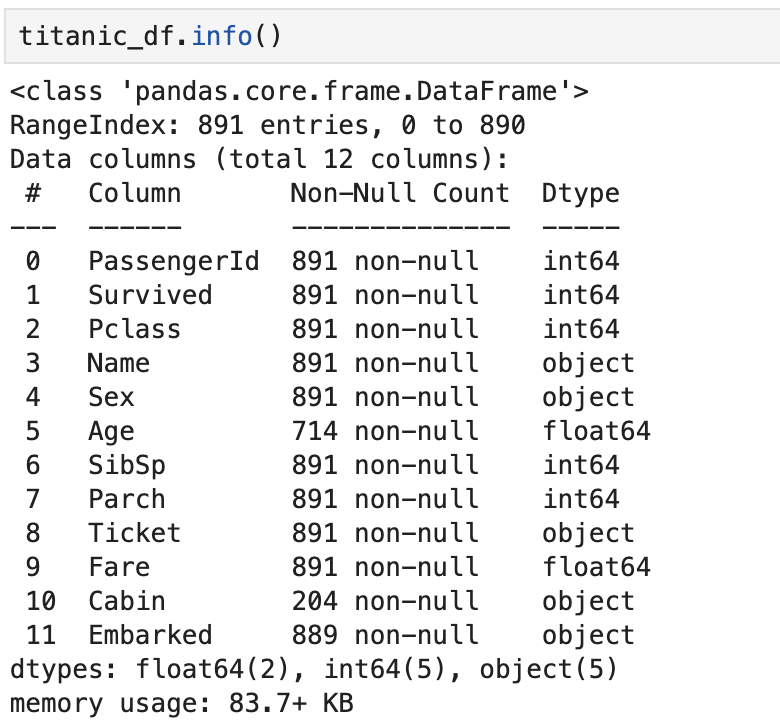
- describe() : 숫자형 칼럼에 대한 개략적인 데이터 분포도 확인

- count : Not Null인 데이터 건수 / mean : 전체 데이터의 평균 / std : 표준편차 / min : 최솟값 / max : 최댓값