앙상블 학습 개요
: 앙상블 학습을 통한 분류는 여러 개의 분류기 (Classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법
쉽게 말해서, 집단 지성을 이용해서 학습하는 것이라고 생각할 수 있다.
앙상블 학습의 유형
- 보팅 (Voting), 배깅(Bagging), 부스팅(Boosting)의 세가지로 나뉜다.
보팅 vs. 배깅
: 보팅과 배깅은 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식
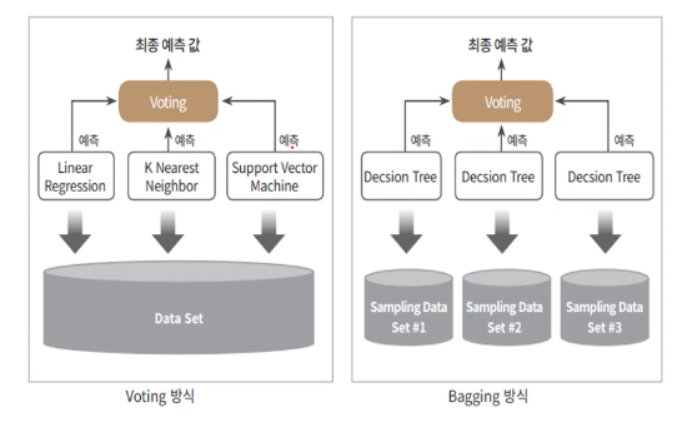
보팅
: 일반적으로 서로 다른 알고리즘을 가진 분류기를 결합하는 것
- 대표적인 예시 : 랜던 포레스트 알고리즘
- 선형회귀, K 최근접 이웃, 서포트 백터 머신이라는 3개의 ML 알고리즘이 같은 데이터 세트에 대해 학습하고 예측한 결과를 가지고 최종 예측 결과를 선정하는 방식
vs.
배깅
: 각각의 분류기가 모두 같은 유형의 알고리즘이지만, 데이터 샘플링을 다르게 가져가면서 학습을 수행해 보팅을 하는 것
- 단일 ML 알고리즘으로 여러 분류기가 학습으로 개별 예측을 진행 but, 학습 데이터 세트가 보팅 방식과는 다르다.
- 부트스트래핑(Bootstrapping) : 개별 Classifier에게 데이터를 샘플링해서 추출하는 방식
- 배깅은 데이터 세트의 중첩을 허용
부스팅 Boosting
: 여러 개의 분류기가 순차적으로 학습을 수행하되, 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해서는 올바르게 예측할 수 있도록 다음 분류기에 가중치 weight를 부여하면서 학습과 예측을 진행하는 것
EX) 그래디어트 부스트, XGBoost(eXtra Gradient Boost), LightGBM(Light Gradient Boost)
스태킹
: 여러가지 다른 모델의 예측 결괏값을 다시 학습 데이터로 만들어서 다른 모델(메타 모델)로 재학습시켜 결과를 예측하는 방법
보팅 유형 - 하드 보팅 Hard Voting 과 소프트 보팅 Soft Voting
하드 보팅 Hard Voting
: 예측한 결괏값들 중 다수의 분류기가 결정한 예측값을 최종 보팅 결괏값으로 선정하는 것
- 다수결의 원칙과 비슷
EX) Classifier 1,3,4이 클래스 1로 레이블 값을 예측하고 2번이 2로 레이블 값을 예측하면 다수결의 원칙에 따라 최종 예측은 1이 된다.
소프트 보팅 Soft Voting
: 분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균내서 이들 중 확률이 가장 높은 레이블값을 최종 보팅 결괏값으로 선정
- 일반적으로 소프트 보팅을 적용 (하드 보팅보다 성능이 우세)
EX) 레이블 값 1의 평균 예측 확률은 (0.7 + 0.2 + 0.8 + 0.9) / 4 = 0.65가 되고 레이블 2의 평균 예측 확률은 같은 방법으로 구하면 0.35가 된다. 레이블 1의 값이 더 크기 때문에 레이블 1로 최종 보팅 진행

보팅 분류기 Voting Classifier
사이킷런에서 보팅 방식의 앙상블을 구현한 VotingClassifier 클래스 제공
보팅 방식의 앙상블을 이용해 위스콘신 유방암 데이터 세트 예측 분석 진행
- 로지스틱 회귀와 KNN을 기반으로 보팅 분류기 생성
위스콘신 유방암 데이터 세트
: 유방암의 악성종양, 양성종양 여부를 결정짓는 이진 분류 데이터 세트
종양의 크기, 모양 등의 형태와 관련한 많은 피처를 가지고 있다.
1. 데이터 불러오기 Data Load

2. 보팅 분류기 만들기
VotingClassifier 클래스 : 주요 생성 인자로 estimators와 voting 값을 입력 받는다.
- estimators : 리스트 값으로 보팅에 사용될 여러 개의 Classifier 객체들을 튜플 형식으로 입력 받음
- voting : 'hard' = 하드보팅, 'soft' = 소프트 방식을 적용 (default = hard)

3. 결과 해석
보팅 분류기의 정확도가 조금 높게 나타났지만 무조건 기반 분류기보다 예측 성능이 향상되지는 X
-> 데이터의 특성과 분포 등 다양한 요건에 따라 오히려 기반 분류기가 더 좋은 정확도를 보여줄 수 있다.
'머신러닝 > 파이썬 머신러닝 완벽 가이드' 카테고리의 다른 글
| Chapter 4.5 GBM (Gradient Boosting Machine) (0) | 2024.05.27 |
|---|---|
| Chapter 4.4 랜덤 포레스트 (0) | 2024.05.27 |
| Chapter 3.4 F1 스코어 (0) | 2024.05.16 |
| Chapter 03. 평가 (0) | 2024.05.09 |
| Chapter 2. 사이킷런으로 시작하는 머신러닝 (1) | 2024.05.01 |